환경 및 준비 : windows 10, tesseract 4.x, jTessBoxEditor, pytessract
pretrained model인 traineddata 는 크게 2종류가 있다.
tessdata_best/kor.traineddata : best model (약 12M)
tessdata_fast/kor.traineddata : integer model (약 1.6M)

https://github.com/tesseract-ocr
tesseract-ocr
tesseract-ocr has 14 repositories available. Follow their code on GitHub.
github.com
1) 기존 모델 test (pytesseract 사용)
* pytesseract 설치 참고
https://wandukong.tistory.com/9


1-1) best model 결과
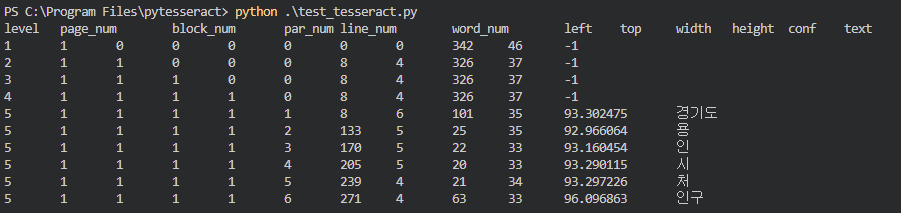
1-2) fast model 결과
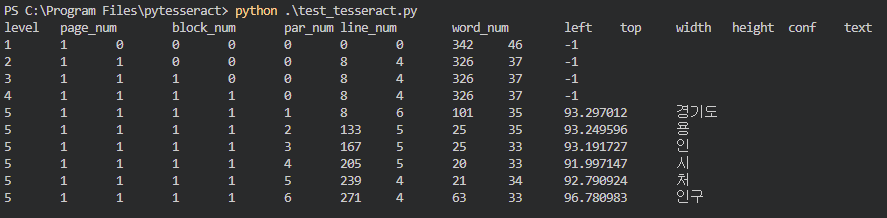
best model confidence 값이 약간 더 높지만 큰차이가 없다.
2) Fine tune 학습
2-1) 학습할 data 준비
jTessBoxEditor로 추가 학습할 이미지와 box파일을 만들어 준다.
바탕체 10point로 진행해 보았다.

generate를 눌러서 파일을 생성해준다.

한글을 영어로 바꿔 준다.

kor.batang.exp0.box 파일과 kor.batang.exp0.tif 파일을 Tesseract-OCR 폴더로 복사한다.
2-2) 학습하기 위한 파일로 변경
.\tesseract kor.batang.exp0.tif kor.batang.exp0 -l kor --psm 6 lstm.traincmd창에서 명령어를 실행하면 kor.batang.exp0.lstmf 파일이 생성된다.
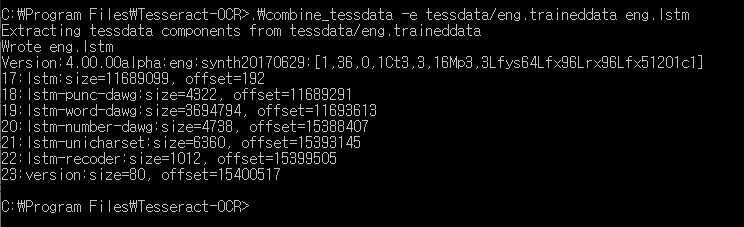
2-3) 기존 kor.traineddata 파일로 kor.lstm 파일 생성
.\combine_tessdata -e tessdata/kor.traineddata kor.lstm

위와 같이 4가지 파일이 있으면 학습 준비 완료
2-4) LSTM 학습(fine tune)
체크포인트가 저장될 model_output 폴더를 생성해준다.
.\lstmtraining --model_output .\model_output/output --continue_from kor.lstm --train_listfile text.training_file.txt --traineddata tessdata/kor.traineddata --debug_interval -1 --max_iterations 1000--model_output : Base path of output model files/checkpoints.
--continue_from : Path to previous checkpoint from which to continue training or fine tune.
--train_listfile : Filename of a file listing training data files.
--traineddata : Path to the starter traineddata file that contains the unicharset, recoder and optional language model.
--debug_interval : If non-zero, show visual debugging every this many iterations.
--max_iterations : Stop training after this many iterations.
위 명령어를 통해 fine tune 학습을 진행 할 수 있다.
* Failed to load list of training filenames from text.training_file.txt 오류가 난다면
Tesseract-OCR 폴더내에 text.training_file.txt 파일을 생성해주고
아래와 같이 kor.batang.exp0.lstmf 파일명을 적어주고 저장한다.

* Compute CTC targets failed for kor.batang.exp0.lstmf! 오류가 난다면
jTessBoxEditor 에서 data 생성할때 글자수를 좀 줄여서 다시 만든다.

위와 같이 글자수를 줄여 학습에 성공했다.
*22-09-23 수정
이상하게 jTessBoxEditor로 box file을 만들면 잘안되는경우가 많았다.
Wordstr로 했을때 성공률이 더 높았음으로 wordstr로 box file 만드는 것을 추천한다.
tesseract kor.batang.exp0.tif kor.batang.exp0 -l kor --psm 6 wordstrbox만들어진 box file을 열어서 확인 해보고 틀린 한글이 있으면 수정한 후에 lstmf 파일을 만들어 준다.
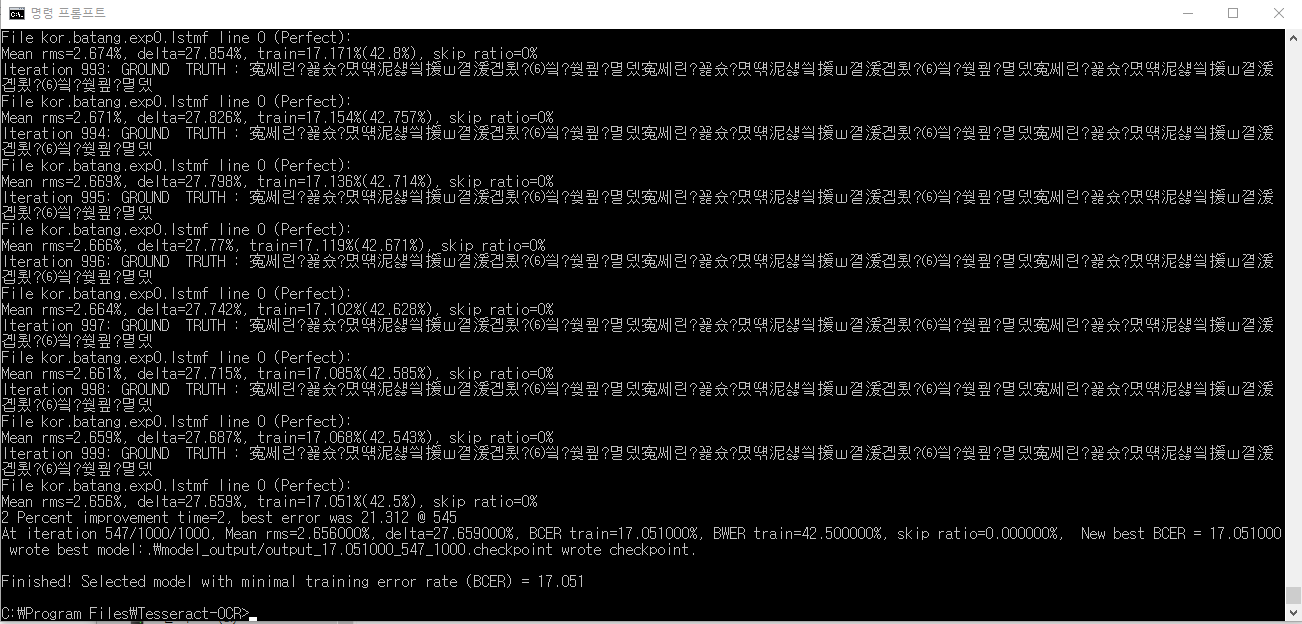
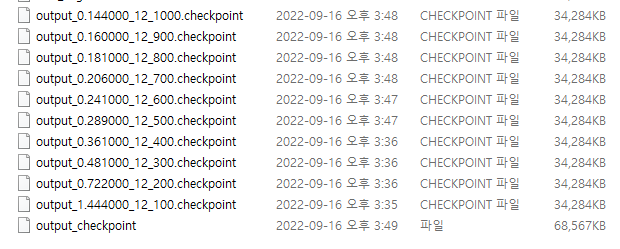
model_output 폴더에 저장된 checkpoint들
2-5) checkpoint to traineddata
.\lstmtraining --stop_training --continue_from .\model_output/output_17.051000_547_1000.checkpoint --traineddata tessdata/kor.traineddata --model_output .\model_output/new_kor.traineddata--continue_from 에 변환할 체크포인트 파일명을 넣고
--model_output 에 생성될 traineddata 파일명을 넣어준다 여기서는 new_kor.traineddata 를 사용했다.

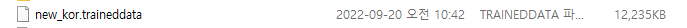
약 12M 의 finetuning 된 traineddata가 생성 되었다.
이 파일을 Tesseract-OCR/tessdata 폴더로 이동하여 TEST를 해보자
3) new traineddata TEST (pytesseract)
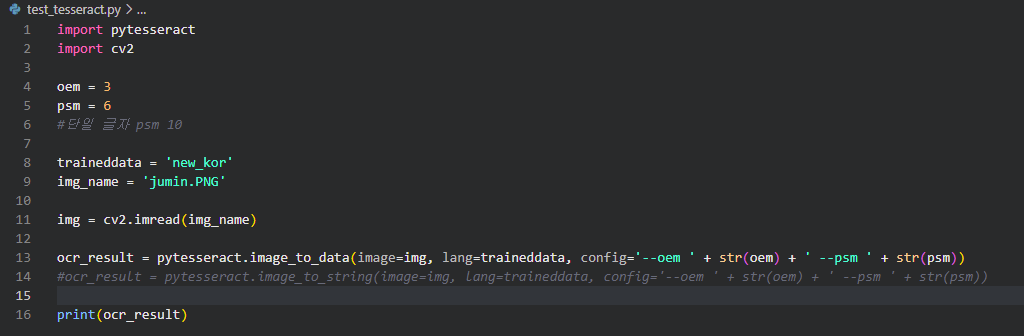
인식은 잘 되나 conf값이 하락하였다.
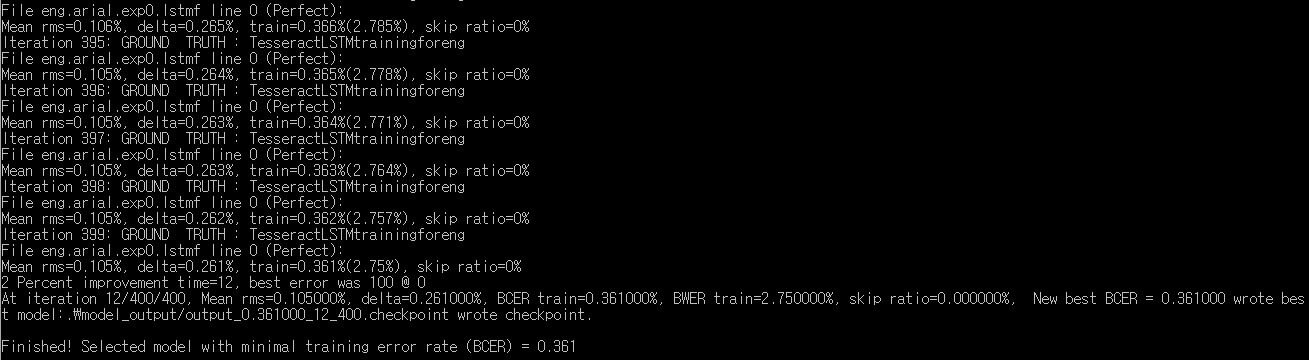
체크포인트 파일명 output 뒤에오는 숫자가 loss값인데 아직 학습이 덜 되어서 정확도가 낮다.
이어서 training을 시켜주자.
4) 체크포인트 불러와서 이어서 학습
.\lstmtraining --model_output .\model_output/output --continue_from .\model_output/output_17.051000_547_1000.checkpoint --train_listfile text.training_file.txt --traineddata tessdata/kor.traineddata --debug_interval -1 --max_iterations 5000--continue_from 에 이어서 학습할 체크포인트 파일명을 넣어 준다.
--max_iterations 에 기존보다 더 큰 숫자를 넣어 준다.
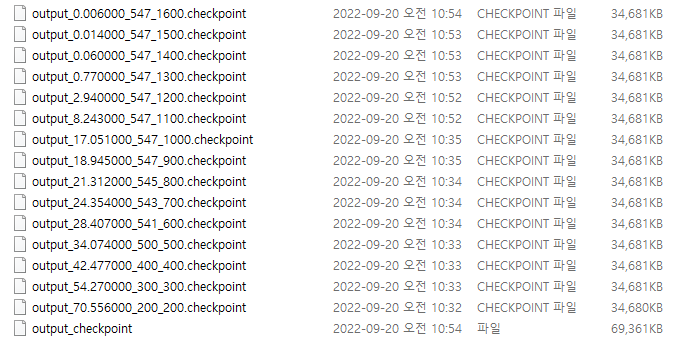
0.006 까지 내려갔다. traineddata로 변환하자
.\lstmtraining --stop_training --continue_from .\model_output/output_0.006000_547_1600.checkpoint --traineddata tessdata/kor.traineddata --model_output .\model_output/new_kor2.traineddatainteger 형으로도 변환
.\lstmtraining --stop_training --continue_from .\model_output/output_0.006000_547_1600.checkpoint --traineddata tessdata/kor.traineddata --model_output .\model_output/new_kor2_int.traineddata --convert_to_int True
뒤에 --convert_to_int True 를 붙여준다

12M -> 2.1M 로 용량이 줄었다.
5) 이어서 학습한 traineddata TEST
5-1) new_kor2.traineddata TEST
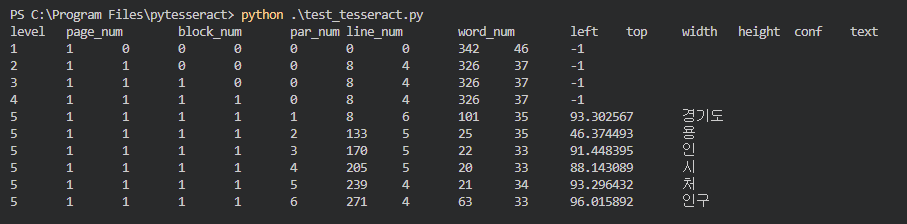
conf 값이 더 떨어졌다...
5-2) new_kor2_int.traineddata TEST

integer model에선 더 좋게 나왔다.
6) 마무리
tesseract 한글 모델 fine tuning하고 TEST하는 방법을 알아보았다.
결과적으로 성능이 떨어졌지만 이후 여러 다른 방법으로 시도해본결과 소폭 상승하기도 하였다.
기타 삽질
jTessboxEditor를 사용하여 추가학습 data를 만들때 같은 글자만 사용하는 것 보단 다양한 글자를 사용할때 좋았다.
LSTM training을 할때 항상 마지막 체크포인트가 최고 성능을 내지는 않았다.
폰트 크기에 따라서 confidence 값 차이가 있었다.
여러개 폰트를 추가해서 fine tune 해봤을때 성능이 좋아지는 경우도 있었지만 안좋아지는 경우도 많았다.
성능을 끌어 올리려면 다양한 조합으로 많은 시도를 해봐야 할 것 같다.
'IT > 인공지능' 카테고리의 다른 글
| tesseract-OCR windows LSTM finetuning 학습 (0) | 2022.09.16 |
|---|---|
| [스크랩] 인공지능, 목적을 이루려 스스로 언어 개발... 사람은 이해 못해 (1) | 2017.06.27 |